[网页去重]网络爬虫过程中5种网页去重方法简要介绍和指纹算法
·
文章编辑:孔宇SEO
·
所属栏目:SEO技术
想做好网站收录,一定要了解去重算法和指纹算法,只有这样才能更好地做好原创网页,帮助网站促进收录,提升排名。对一个新的网页,爬虫程序通过网页去重算法,最终决定是否对其索引。
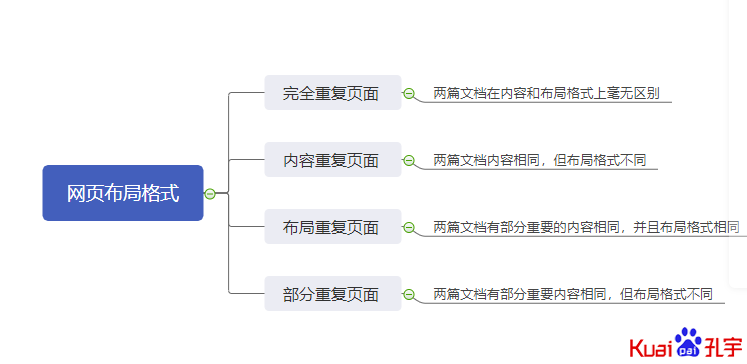
一、近似重复网页类型,根据文章内容和网页布局格式的组合分为4种形式:
1、两篇文档在内容和布局格式上毫无区别,则这种重复称为完全重复页面。
2、两篇文档内容相同,但布局格式不同,则这种重复称为内容重复页面。
3、两篇文档有部分重要的内容相同,并且布局格式相同,则这种重复称为布局重复页面。
4、两篇文档有部分重要内容相同,但布局格式不同,则这种重复称为部分重复页面。
二、重复网页对搜索引擎的不利影响:
正常情况下,非常相似的网页内容不能或只能给用户提供少量的新信息,但在对爬虫进行抓取、索引和用户搜索会消耗大量的服务器资源。
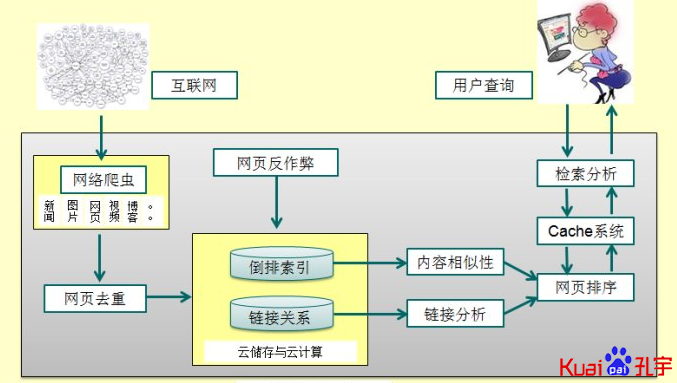
三、重复网页对搜索引擎的好处:
如果某个网页重复性很高,往往是其内容比较比较受欢迎的一种体现,也预示着该网页相对比较重要。应予以优先收录。当用户搜索时,在输出结果排序时,也应给与较高的权重。
四、重复文档的处理方式:
1、删除
2、将重复文档分组
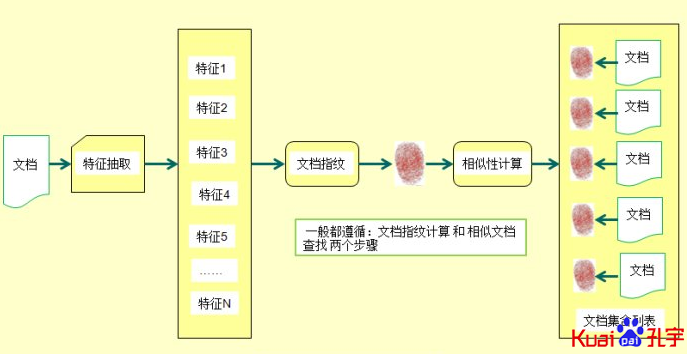
五、 SimHash文档指纹计算方法 :
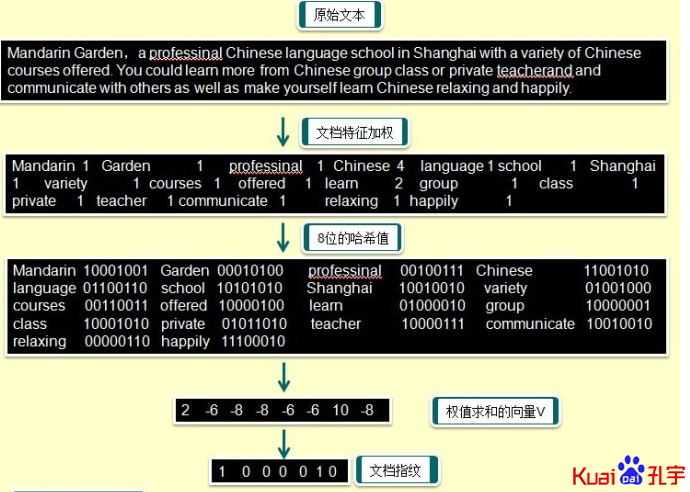
1、从文档中提取具有权值的特征集合来表示文档。如:假设特征都是由词组成的,词的权值由词频TF来确定。
2、对每一个词,通过哈希算法生成N位(通常情况是64位或更多)的二进制数值,如上图,以生成8位的二进制值为例。每个词都对应各自不同的二进制值。
3、在N维(上图为8维)的向量V中,分别对每维向量进行计算。如果词相应的比特位的二进制数值为1,则对其特征权值进行加法运算;如果比特位数值为0,则进行减法运算,通过这种方式对向量进行更新。
4、当所有的词都按照上述处理完毕后,如果向量V中第i维是正数,则将N位的指纹中第i位设置为1,否则为0。

一般的,我们想抓取一个网站所有的URL,首先通过起始URL,之后通过网络爬虫提取出该网页中所有的URL链接,之后再对提取出来的每个URL进行爬取,提取出各个网页中的新一轮URL,以此类推。整体的感觉就是自上而下进行抓取网页中的链接,理论上来看,可以抓取整站所有的链接。但是问题来了,一个网站中网页的链接是有环路的。
首先介绍一个简单的思路,也是经常用的一个通用思路。我们将已经爬取过的网页放到一个列表中去,以首页为例,当首页被抓取之后,将首页放到列表中,之后我们抓取子网页的时候,如果再次碰到了首页,而首页已经被抓取过了,此时就可以跳过首页,继续往下抓取其他的网页,而避开了将首页重复抓取的情况,这样下来,爬取整站就不会出现一个环路。以这个思路为出发点,将访问过的URL保存到数据库中,当获取下一个URL的时候,就去数据库中去查询这个URL是否已经被访问过了。虽然数据库有缓存,但是当每个URL都去数据库中查询的话,会导致效率下降的很快,所以这种策略用的并不多,但不失为最简单的一种方式。
第二种方式是将访问过的URL保存到set中去,通过这样方式获取URL的速度很快,基本上不用做查询。但是这种方法有一个缺点,将URL保存到set中,实际上是保存到内存中,当URL数据量很大的时候(如1亿条),会导致内存的压力越来越大。对于小型的爬虫来说,这个方法十分可取,但是对于大型的网络爬虫,这种方法就难以企及了。
第三种方式是将字符进行md5编码,md5编码可以将字符缩减到固定的长度。一般来说,md5编码的长度约为128bit,约等于16byte。在未缩减之前,假设一个URL占用的内存大小为50个字节,一个字节等于2byte,相当于100byte。由此可见,进行md5编码之后,节约了大量的内存空间。通过md5的方式可以将任意长度的URL压缩到同样长度的md5字符串,而且不会出现重复的情况,达到去重的效果。通过这种方式很大程度上节约了内存,scrapy框架采取的方式同md5方式有些类似,所以说scrapy在正常情况下,即使URL的数量级达到了上亿级别,其占用的内存比起set方式也要少得多。
第四种方式是使用bitmap方法将字符进一步压缩。这种方式的意思是在计算机中申请8个bit,即8个位,每个位由0或者1表示,这是计算机中最小的单元。8个位组成1个byte,一个位代表一个URL的话,为什么一个位可以确定一个URL呢?因为我们可以将一个URL进行一个哈希函数,然后将其映射到位上面去。举个栗子,假设我们有8个URL,分别对应8个位,然后通过位上面的0和1的状态,便可以表明这个URL是否存在,通过这种方法便可以进一步的压缩内存。但是bitmap方法有一个非常大的缺点,就是它的冲突会非常高,因为同用一个哈希函数,极有可能将两个不同的URL或者多个不同的URL映射到一个位置上来。实际上这种哈希的方法,它也是set方式的一种实现原理,它将URL进行一种函数计算,然后映射到bit的位置中去,所以这种方式对内存的压缩是非常大的。简单的来计算一下,还是以一亿条URL来进行计算,相当于一亿个bit,通过计算得到其相当于12500000byte,除以1024之后约为12207KB,大概是12MB的空间。在实际过程中内存的占用可能会比12MB大一些,但是即便是如此,相比于前面三种方法,这种方式以及大大的减少了内存占用的空间了。但是与此同时,该方法产生冲突的可能性是非常大的,所以这种方法也不是太适用的。那么有没有方法将bitmap这种对内存浓重压缩的方法做进一步优化,让冲突的可能性降下来呢?答案是有的,就是第五种方式。
第五种方式是bloomfilter,该方法对bitmap进行改进,它可以通过多个哈希函数减少冲突的可能性。通过这种方式,一方面它既可以达到bitmap方法减少内存的作用,另一方面它又同时起到减少冲突的作用。关于bloomfilter原理及其实现,后期肯定会给大家呈上,今天先让大家有个简单的认识。Bloomfilter适用于大型的网络爬虫,尤其是数量级超级大的时候,采用bloomfilter方法可以起到事半功倍的效果,其也经常和分布式爬虫共同配合,以达到爬取的目的。


